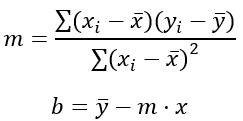La covarianza es una medida estadística que te ayuda a entender cómo dos variables cambian juntas. Imagina que tienes dos variables, como la temperatura y el consumo de helado. Si cuando la temperatura sube, el consumo de helado también sube, entonces las variables tienen una covarianza positiva. Si, por el contrario, cuando la temperatura sube, el consumo de helado baja, entonces tienen una covarianza negativa.
La covarianza te dice si las variables tienden a cambiar en la misma dirección (positiva) o en direcciones opuestas (negativa). Si no hay un patrón claro en cómo cambian juntas, entonces la covarianza será cercana a cero, lo que significa que no hay una relación lineal fuerte entre las variables.
¿Cómo se calcula la covarianza?
Para calcular la covarianza entre dos variables, necesitas tener un conjunto de datos que incluya los valores de ambas variables. Luego, sigue estos pasos:
- Calcula la media (promedio) de cada variable. Suma todos los valores de cada variable y divide el resultado entre el número total de datos. Esto te dará la media de cada variable.
- Resta la media de cada variable a cada valor correspondiente. Este paso implica restar la media de la variable X a cada valor de X, y hacer lo mismo para la variable Y.
- Multiplica los resultados del paso anterior. Para cada valor restado en el paso anterior, multiplica el resultado correspondiente de la otra variable restada.
- Suma los productos del paso anterior. Suma todos los productos obtenidos en el paso anterior para obtener un valor total.
- Divide el valor obtenido en el paso anterior entre el número total de datos. Este valor es la covarianza entre las dos variables.
Recuerda que la covarianza puede ser positiva, negativa o cercana a cero. Una covarianza positiva indica que las variables tienden a cambiar en la misma dirección. Por otro lado, una covarianza negativa indica que las variables tienden a cambiar en direcciones opuestas. Finalmente, una covarianza cercana a cero indica que no hay un patrón claro en cómo cambian juntas.
Veamos un ejemplo para entender mejor
Imaginemos que tenemos dos variables, “horas de estudio” (X) y “calificación en un examen” (Y), y tenemos los siguientes datos para un grupo de 5 estudiantes:
Horas de estudio (X): 4, 6, 3, 7, 5.
Calificación en el examen (Y): 85, 90, 80, 95, 88.
Paso 1: Calcula la media de cada variable
Media de X: (4 + 6 + 3 + 7 + 5) ÷ 5 = 5
Media de Y: (85 + 90 + 80 + 95 + 88) ÷ 5 = 86
Paso 2: Resta la media de cada variable a cada valor correspondiente
X – Media de X: -1, 1, -2, 2, 0
Y – Media de Y: -1, 4, -6, 9, 2
Paso 3: Multiplica los resultados obtenidos en el paso anterior
(-1) · (-1) = 1
1 · 4 = 4
(-2) · (-6) = 12
2 · 9 = 18
0 · 2 = 0
Paso 4: Suma los productos obtenidos en el paso anterior
1 + 4 + 12 + 18 + 0 = 35
Paso 5: Divide el valor obtenido en el paso anterior entre el número total de datos
35 ÷ 5 = 7
Entonces, la covarianza entre las variables “horas de estudio” y “calificación en el examen” es 7.
¿Cuál es la diferencia entre la varianza y la covarianza?
La varianza es una medida que indica la dispersión estadística o variabilidad de un conjunto de datos. Se calcula como la media de los cuadrados de las desviaciones de los valores individuales con respecto a la media. Una varianza alta significa que los datos están dispersos o alejados de la media, mientras que una varianza baja significa que los datos están más cercanos a la media.
Por otro lado, la covarianza es una medida que indica cómo dos variables se mueven juntas. Es una medida de la variación conjunta de dos variables. Si la covarianza es positiva, indica que ambas variables tienden a aumentar o disminuir juntas. Si la covarianza es negativa, indica que una variable tiende a aumentar cuando la otra disminuye. Una covarianza cercana a cero indica que las variables no tienen una relación lineal fuerte.
En resumen, la varianza mide la variabilidad de un conjunto de datos en sí mismo, mientras que la covarianza mide la relación de variación conjunta entre dos variables.
¿Cuál es la importancia de la covarianza?
La covarianza es una medida importante en estadística y análisis de datos debido a varias razones. Generalmente, es utilizada para evaluar la fuerza y dirección de la relación entre dos variables. Un valor de covarianza cercano a cero indica una relación débil o nula, mientras que un valor alto en magnitud indica una relación fuerte entre las variables.
Por otro lado, cabe mencionar que, es una herramienta útil en la modelización y predicción de datos. Puede ser empleada en técnicas avanzadas de análisis de datos, como regresión lineal y análisis de series temporales, para entender cómo los cambios en una variable pueden afectar a otra variable.
Asimismo, tiene gran importancia en la gestión de riesgos financieros. Permite evaluar cómo se mueven dos activos financieros en conjunto, lo cual es fundamental en la diversificación de carteras de inversión y en la evaluación del riesgo y rendimiento de diferentes activos.
¿Cuáles son los principales usos de la covarianza?
La covarianza es una herramienta importante en el análisis de datos y tiene varios usos. Uno de los principales empleos de la covarianza es en la estadística y la econometría. Se utiliza para medir la relación de variación conjunta entre dos variables, lo que puede ayudarnos a entender cómo se mueven juntas.
En el campo de las finanzas, la covarianza es utilizada para evaluar la relación entre los rendimientos de diferentes activos financieros, como acciones, bonos o bienes raíces. Ayuda a los inversores a entender cómo se comportan los activos en conjunto y cómo se pueden diversificar las inversiones para gestionar el riesgo.
En el análisis de riesgo y gestión de carteras, la covarianza es utilizada para calcular la diversificación de riesgo, es decir, cómo se correlacionan los rendimientos de diferentes activos. Una baja covarianza entre dos activos indica que son menos propensos a moverse en la misma dirección, lo que puede ser beneficioso para reducir el riesgo de la cartera.
Además, la covarianza también se usa en áreas como la ciencia ambiental, la biología, la psicología y la ingeniería, donde se estudian las relaciones entre diferentes variables para comprender su comportamiento y hacer predicciones.
Es importante tener en cuenta que la covarianza tiene algunas limitaciones, como no ser una medida estandarizada y no capturar relaciones no lineales entre variables. Sin embargo, sigue siendo una herramienta valiosa en el análisis de datos para comprender cómo se mueven juntas dos variables y su relación de variación conjunta.
Propiedades de la covarianza
Veamos algunas de las propiedades más importantes de la covarianza, a continuación:
- La covarianza entre dos variables puede ser positiva, lo cual indica que tienden a moverse en la misma dirección. Por otro lado, si la covarianza es negativa, significa que tienden a moverse en direcciones opuestas. Si la covarianza es cero, no hay una relación lineal entre las variables.
- A diferencia de la correlación, la covarianza no está limitada a un rango específico y no tiene unidades de medida estandarizadas. Esto puede hacer que sea difícil comparar covarianzas de diferentes escalas o unidades.
- La presencia de valores extremos o atípicos en los datos puede tener un impacto significativo en la covarianza. Esto puede causar que la covarianza sea alta o baja, incluso si la relación entre las variables no es fuerte.
- La covarianza entre dos variables es simétrica, lo que significa que la covarianza de X con respecto a Y es igual a la covarianza de Y con respecto a X. Esto se debe a que la covarianza se basa en la variación conjunta de ambas variables.
- Es importante tener en cuenta que la covarianza no implica necesariamente una relación causal entre las variables. Solo muestra la dirección y magnitud de la variación conjunta entre las variables, pero no establece una relación causal directa.
Ejemplo de covarianza
Como ya sabemos, todo se entiende más claro cuando usamos ejemplos. Por ello, vamos a analizar este ejemplo sencillo de covarianza para una mejor comprensión.
Vamos a considerar dos nuevas variables, A y B, con los siguientes datos:
A = (a1, a2, a3) = (2, 5, 7)
B = (b1, b2, b3) = (6, 3, 1)
Primero, vamos a calcular la media aritmética de cada una de las variables:
A’ = (2 + 5 + 7) ÷ 3 = 4,67
B’ = (6 + 3 + 1) ÷ 3 = 3,33
Una vez que hemos calculado las medias aritméticas, procedemos a calcular la covarianza:
Cov(A, B) = (2 – 4,67) · (6 – 3,33) + (5 – 4,67) · (3 – 3,33) + (7 – 4,67) · (1 – 3,33) ÷ 3 = -2,33
En este caso, el valor de la covarianza es negativo. Esto indica que las variables A y B tienen una relación negativa, lo que significa que cuando una variable aumenta, la otra variable tiende a disminuir. Sin embargo, para comprender mejor la relación entre A y B, es necesario calcular la correlación lineal.
También es relevante tener en cuenta que no se pueden comparar las covarianzas de variables diferentes, ya que la unidad de medida de la covarianza es la misma que la de las variables en cuestión. Por lo tanto, no se puede comparar la covarianza de variables como el ingreso y la edad, por ejemplo, debido a sus diferentes unidades de medida.